Aqours 歌词词频统计与分析
引言
随着二期アニメ放送,水学研究进入新阶段。现今水学研究多着眼于对一首歌词情感分析,在整体统计领域鲜见研究。因此本文使用统计学手法对全曲歌词进行词频统计,希望能对 Aqours 词风进行更深刻的分析。
歌词获取
黄易云音乐是我朝较流行在线音乐服务,对于歌词获取相关 API 较完善,故选用本服务进行歌词爬取。由于 Aqours 曲目中存在广播剧、伴奏等无关内容,因此不宜从单曲进行获取。在黄易云上有许多水水人整理好的歌单,因此直接利用。
获取思路:
- 由歌单id获取歌曲id
- 由歌曲id获得歌词
利用 requests 即可抓取网页,由此获得 id。参考相关代码,作 getMusicID、getLyrics函数。获取歌词写入文本。
分词
日语分词工具 MeCab 对 python 支援较好,因此选用本工具。在歌词中只有名词、形容词、动词对曲风分析有意义,因此还需对词性分析。参考 iruca さん的文章作extractWord、makeHistogram、map2Csv函数。分词获取指定词性词汇,用 Counter 统计次数,转换为 string 用于存储。
由于 mecab 一次只分析一句话,因此将歌词合并成一个 string 后分析。
取得词频信息结构为
| word | count |
|---|---|
| 夢 | 5 |
统计作图
此时获得词频信息后就可以作图。这里使用 pandas 对数据进行排序,之后还有合并数据用途。这里使用os.listdir函数获取到目录所有文件,注意排除如.DS_Store等隐藏文件的干扰。之后使用 matplotlib 画柱状图。由于歌曲词量较多,可以选取前50作图。
全统计
由于先前只是统计单首歌曲词频,要对全曲分析需进行合并。使用 pandas 读取各曲数据合并。由于各曲词汇不同,在 merge 时使用 outer 合并。由此产生多列与NaN,偷懒倒出后用 Numbers.app 统计求和。之后将总和数据读入、排序后作图。
分析
排除语法成分后作图得
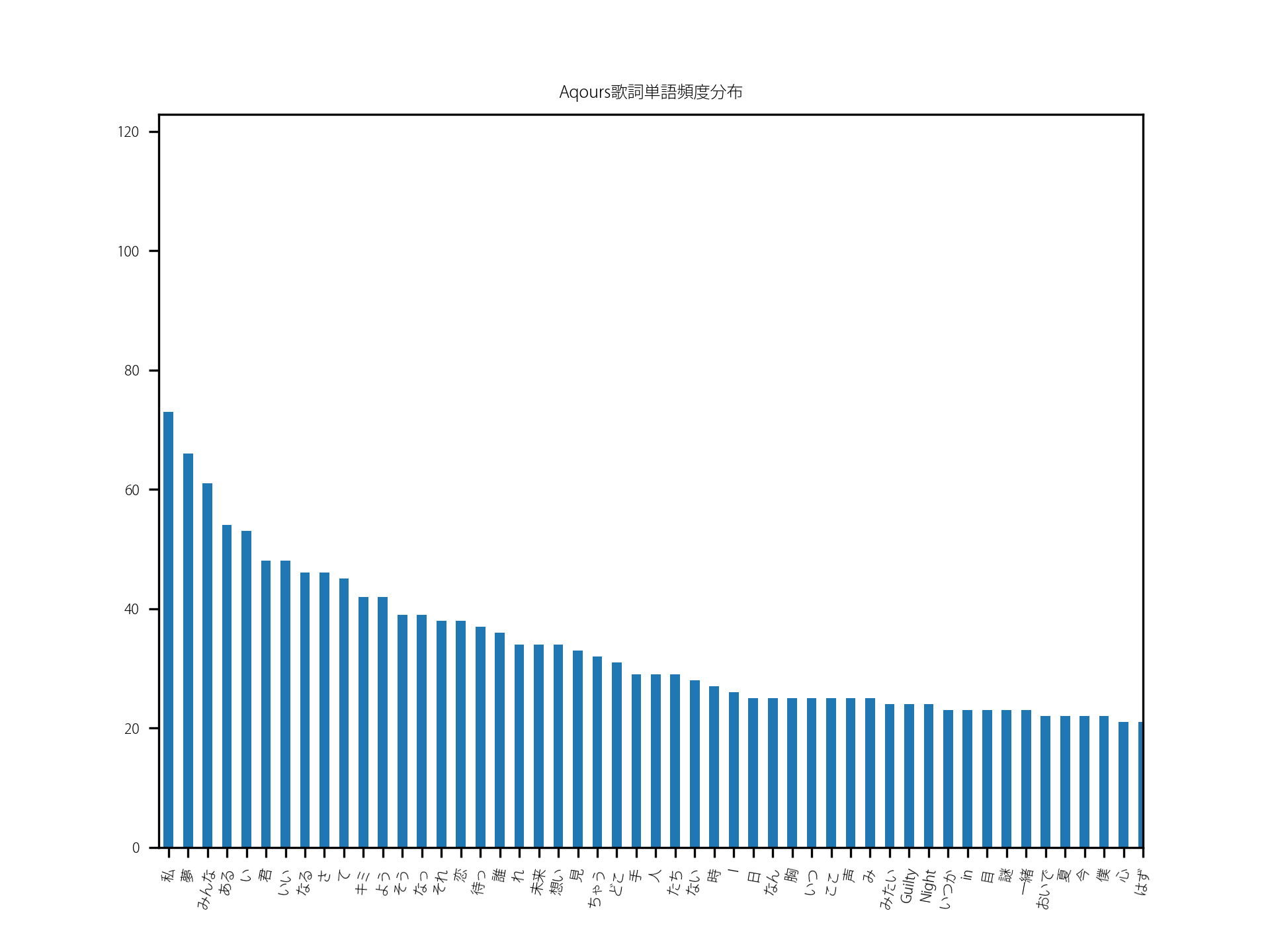
观察前50词,出现的为私、夢、みんな、ある、君、いい、なる、キミ、恋、待っ、誰、未来、想い、見、手、人、たち、時、I、胸、ここ、声、みたい、Guilty、Night、いつか、目、謎、一緒、夏、今、僕、心等意象。由此可见 aqours 以梦想为主要题材,正应了黛雅所说需要创新(二期5话)。次之有みんな、君、人、たち表明与他人的互动,既是 aqours 的众人也是与我们水水人。再看有恋、未来、想い、時、胸、声等意象让人联想到一期插曲、二单,也是说明 aqours 的追梦情节。可见 aqours 词风还是十分正统偶像风。
结论
本文通过抓取歌词、词频分析成功分析了 aqours 全曲词风,使用统计学方法使研究成果更具科学性。
附录
全曲统计信息与作图信息已打包上传至mega,可下载分析。地址
其中 all.csv 为单纯合并数据、total.csv 为去多余列数据。
代码全部上传 github ckyOL/aqoursLyricsCount